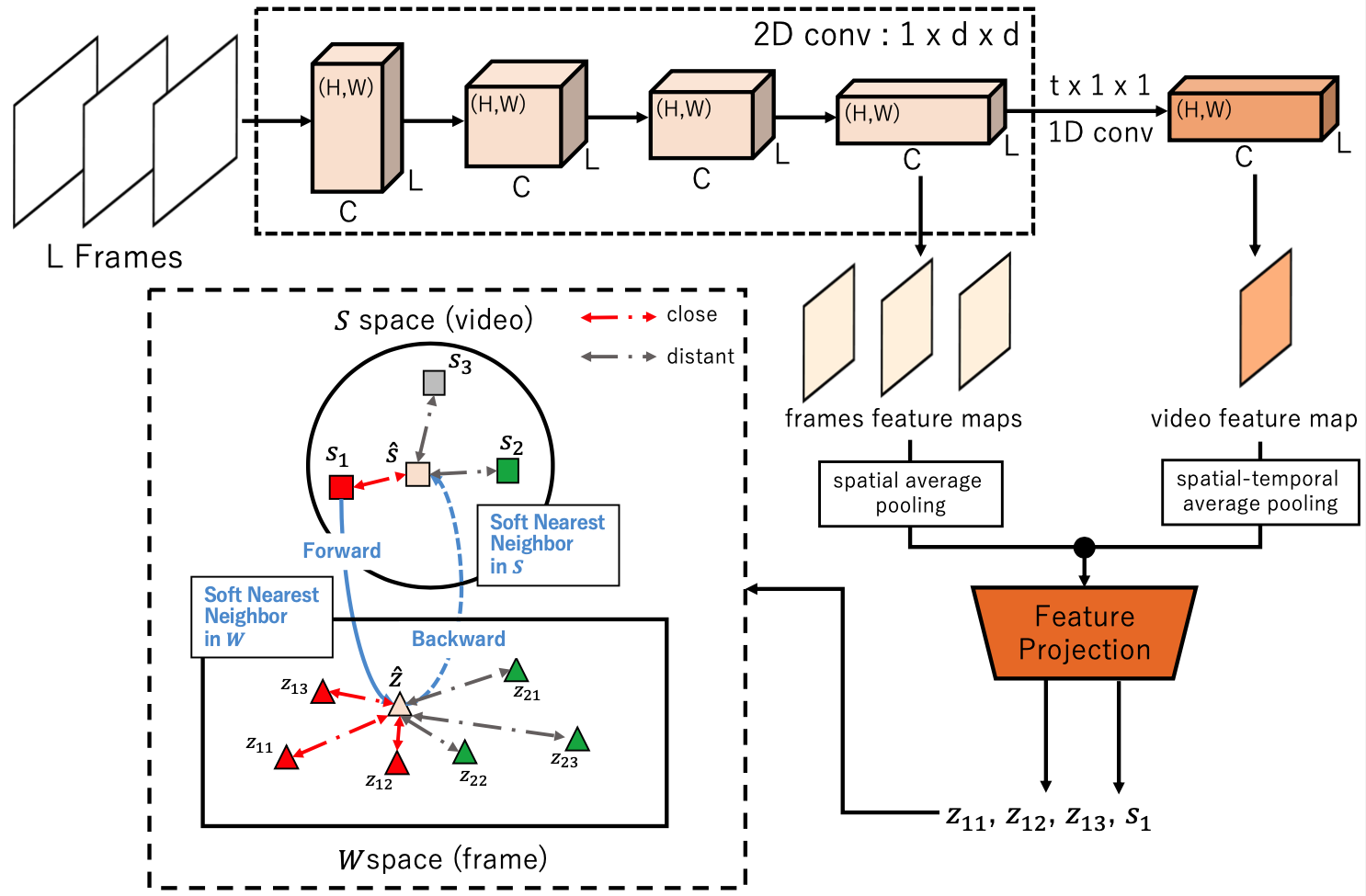
Cycle-Contrastive Learning - Learn a video representation is supposed to be closed across video and its frames yet distant to all the other videos and frames in corresponding domain, respectively.
Abstract
Cycle-Contrastive Learning (CCL) is a self-supervised method for learning video representation. Following a nature that there is a belong and inclusion relation of video and its frames, CCL is designed to find correspondences across frames and videos considering the contrastive representation in their domains respectively. It is different from recent approaches that merely learn correspondences across frames or clips. In our method, the frame and video representations are learned from a single network based on an R3D architecture, with a shared non-linear transformation for embedding both frame and video features before the cycle-contrastive loss. We demonstrate that the video representation learned by CCL can be transferred well to downstream tasks of video understanding, outperforming previous methods in nearest neighbour retrieval and action recognition on UCF101, HMDB51 and MMAct.